Il Machine Learning Model Designer (MLMD) è disponibile dalla versione 2020.00 e consente di creare e classificare con pochi click i modelli dei dati dai quali si vogliono ricavare stime e previsioni.

Le funzionalità principali del modulo sono le seguenti:
- Classificazione dei modelli attribuendo un codice, una descrizione breve e una descrizione estesa;
- Definizione del tipo di Machine Learning: Classificazione Multiclasse, Regressione, Classificazione Binaria;
- Associazione della query che fornisce i dati per il training;
- Scelta dei possibili algoritmi da valutare e della metrica di valutazione;
- Pianificazione della rigenerazione automatica del modello con relativa periodicità (la rigenerazione verrà effettuata da QualiWare Server Daemon);
- Possibilità di allegare documenti a ciascun modello.
Tipo di Machine Learning
Il tipo di Machine Learning può essere:
- Classificazione Multiclasse: si utilizza quando la variabile da stimare è scelta fra un numero limitato di valori stringa;
- Regressione: si utilizza quando la variabile da stimare è un numero (intero o in virgola mobile);
- Classificazione Binaria: si utilizza quando la variabile da stimare è binaria (0 o 1).
Come realizzare la query
La query che specifica i dati “da imparare” (training) può essere utilizzata con il Query Designer e deve avere una struttura ben precisa: le prime N-1 colonne devono contenere le variabili indipendenti (i cosiddetti “predittori”), mentre la N-esima colonna deve contenere la variabile dipendente, quella che verrà stimata.
Le variabili indipendenti possono essere di diversi tipi:
- testo categorizzato;
- testo libero;
- numerico, nel qual caso devono obbligatoriamente avere il tipo di dati SQL “real”;
- logico (0 o 1).
Come si può vedere, le variabili di tipo testo possono essere di due tipi: categorizzato o libero. Il primo tipo corrisponde al caso in cui il valore è scelto all’interno di un insieme limitato di possibili valori. Nel secondo caso, invece, il testo può essere qualsiasi (ad es. quando la variabile contiene un elenco di codici articolo presi da una distinta base, oppure il testo di una mail). Il sistema è in grado di gestire automaticamente in modo appropriato queste due situazioni, che richiedono una modalità di training completamente diversa.
Ovviamente la query non può contenere parametri, in quanto viene eseguita dal sistema senza la possibilità di interagire con l’utente.
Gli algoritmi e la metrica di valutazione
Il modello ottimale viene scelto applicando una serie di algoritmi dei quali vengono stimati i cosiddetti “iper-parametri” (anche più set di valori per lo stesso algoritmo) e viene stimata l’affidabilità sulla base di una “metrica”. Per ogni tipo di Machine Learning sono disponibili algoritmi diversi, che l’utente può selezionare (per saperne di più vedere qui). Al momento della generazione del modello, ogni algoritmo selezionato verrà eseguito con uno o più set di parametri, sulla base del tempo massimo per il training specificato (più elevato è, e più set di parametri verranno provati). Per il training stesso, il sistema non utilizza tutti i dati restituiti dalla query, ma solo una parte, e con la restante parte prova ad eseguire la stima, misurando poi la differenza fra la stima stessa e il valore reale. L’insieme delle differenze consente di calcolare una serie di indicatori della bontà del modello. Tali indicatori sono anch’essi differenti a seconda del tipo di Machine Learning utilizzato, e se ne può trovare una descrizione qui. Ad esempio, nel caso di “Regressione”, l’indicatore RootMeanSquaredError rappresenta la radice quadrata della media dei quadrati degli errori, ed è espressa nella stessa unità di misura della variabile da predire. Se si sta predicendo un valore in metri, tale indicatore sarà anch’esso espresso in metri.
In fase di configurazione del modello si dovrà scegliere, dall’apposita tendina Metrica di ottimizzazione, uno di questi indicatori come metrica di valutazione per stabilire qual è il modello migliore, quello che verrà memorizzato e poi utilizzato per le previsioni.
Generazione del modello
Il processo di valutazione e generazione del modello può essere attivato sia manualmente che automaticamente. L’attivazione manuale viene effettuata premendo il pulsante Genera modello. Durante l’esecuzione verranno mostrati in tempo reale tutti i passaggi effettuati, e, quindi, gli algoritmi valutati e il valore della metrica.
Al termine dell’elaborazione verrà mostrato un dettaglio riepilogativo del modello migliore in base alla metrica stessa, e verranno riportati i valori di tutti gli indicatori.
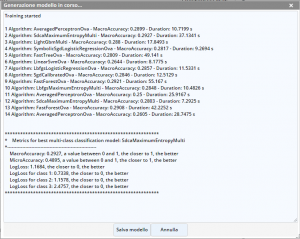
Premendo il pulsante Salva modello, il modello migliore verrà salvato e sarà utilizzato per le stime. Premendo Annulla verrà mantenuto quello precedentemente salvato.
È anche possibile effettuare una rivalutazione automatica periodica, che sarà eseguita da QualiWare Server Daemon, attivando il flag Rigenerazione automatica del modello e specificando, nell’apposito campo, la frequenza di rivalutazione. È anche possibile fare inviare una mail al Redattore al termine dell’operazione.
È possibile verificare lo storico di tutte le generazioni, anche quelle automatiche, consultando la “Cronologia”.
Il pulsante Test modello apre la scheda di test del modello generato, che consente di specificare i valori dei predittori e di effettuare da essi la stima utilizzando la primitiva QWml.Prediction come spiegato qui sotto.
NOTA
Data la complessità degli algoritmi, è possibile che in fase di “training” vengano restituiti errori dovuti al fatto che i dati non sono applicabili al set di dati o a valori degli iper-parametri che il sistema prova ad utilizzare. Per evitare questo problema, provare ad escludere ad uno ad uno gli algoritmi oppure, nel caso in cui l’errore si verifichi in un passaggio successivo al primo, diminuire il tempo massimo per il training.
Utilizzo dei modelli e primitiva QWml.Prediction
Abbiamo detto che il fine ultimo dei modelli è quello di effettuare previsioni. Queste possono essere effettuate in qualsiasi script (eventi Form Designer, Task, ecc.) utilizzando la primitiva QWml.Prediction,
È possibile vedere un esempio di applicazione in questo snippet.